
本文将深入解析大语言模型(LLM)训练所需的架构与基础设施,重点讨论代理服务器在数据采集中的作用,以及它如何帮助系统实现可扩展性。LLM 需要在海量文本上训练(例如 GPT-3,大约 3000 亿 token ≈ 45 TB 文本),因此数据管道通常包含多阶段处理:抓取、清洗、去重、过滤、分词以及分布式训练。代理是这条管道的基石,因为它能够支撑大规模网页数据采集、降低被封禁风险、控制地理位置,并均衡分配负载。
我们将覆盖 LLM 管道的全部阶段(从数据采集与准备,到分布式训练、安全、监控与部署),并说明代理应该在什么位置、因何原因被使用。我们还会单独分析代理类型(住宅、数据中心、移动),以及它们的性能与典型应用场景。此外,我们会用表格对五家领先代理服务商在 LLM 相关任务中的表现进行对比。
没时间细看?NodeMaven 是用于 LLM 训练的最佳代理服务商。
LLM 数据管道的阶段
训练 LLM 的第一步,是从多种来源构建一个大型文本语料库:Common Crawl、各类网站、百科全书、科研论文、书籍、代码仓库等。但仅仅把整个互联网“搬下来”还不够,数据必须足够新、足够多样且质量可靠。因此,许多实验室会持续抓取新页面,让模型保持更新(否则,像 GPT-4 这种只训练到 2021 年数据的模型,就无法回答 2025 年发生的事件)。
LLM 的数据处理管道通常包含以下关键步骤:
-
抓取 – 通过网络下载原始 HTML/JSON/媒体内容;
-
清洗 – 去除 HTML 模板、广告与脚本;
-
去重 – 移除完全重复与近似重复的文档;
-
过滤 – 按质量筛选,排除有毒内容或个人信息内容,并按语言等维度筛选;
-
训练 – 分词并在 GPU/TPU 集群上训练。上述每个阶段都需要良好的基础设施设计与监控体系支撑。
下面给出该管道的示意图(重点展示代理的作用):
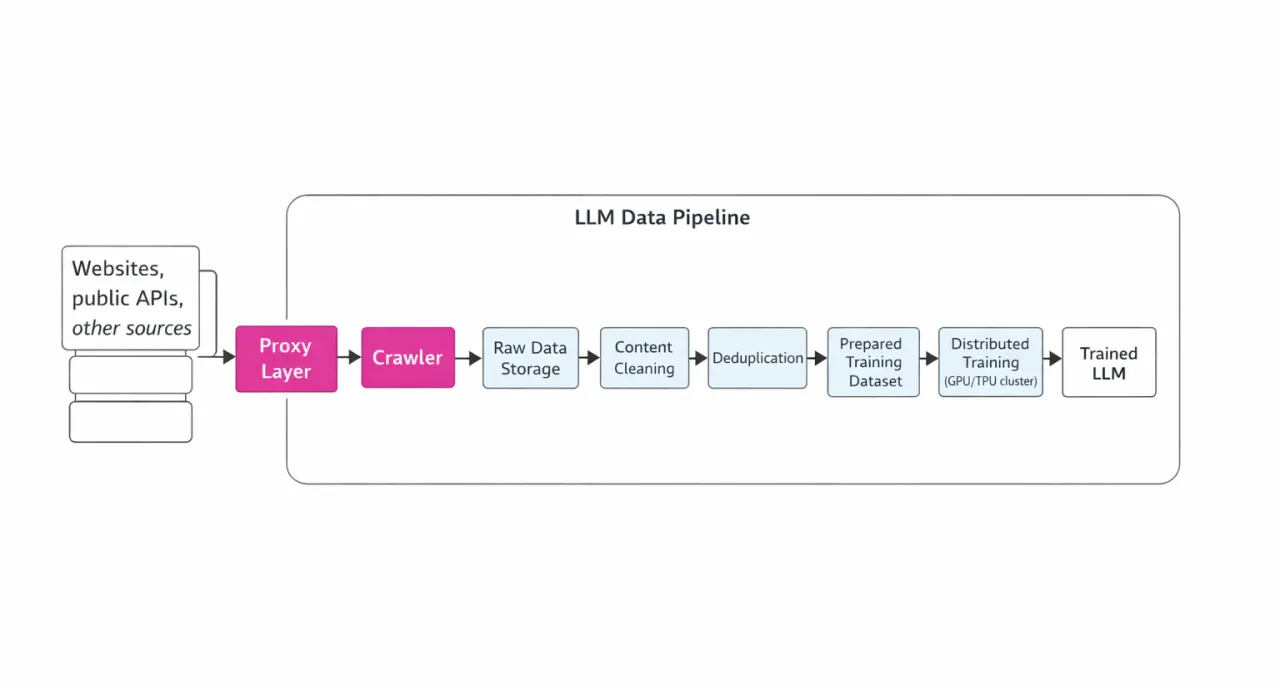
抓取与代理的作用
在抓取阶段,通常需要同时向不同网站发送数百万级的 HTTP(S) 请求。然而,反爬机制与基于 IP 的限制往往会阻断大规模采集。这时就需要用到代理服务器。代理能够把请求分散到成千上万的 IP 地址与不同地理位置上,从而显著降低被封的概率。尤其是轮换代理至关重要,它支持不中断的持续采集。代理还能更好地模拟真实用户请求,降低被识别的风险。即使是访问 API(例如调用其他服务,或用 LLM 生成合成数据),代理也能帮助分摊负载并遵守速率限制。
但需要强调的是:代理解决的是技术层面的限制(IP 封禁、速率限制、本地化),并不会绕过法律限制。使用代理并不意味着可以不遵守 robots.txt 与相关法律法规,因此即便使用代理采集数据,也应当尊重网站规则与合规要求。
数据处理(清洗、过滤、去重)
收集到原始内容后,进入预处理阶段。例如 AWS 曾描述“管道的第一步是从各种来源与格式(PDF、HTML、JSON、Office 文档)中提取并汇聚数据”,并会使用 OCR、HTML 解析器等工具。在这一阶段,会移除不需要的元素(HTML 标签、非英文字符等),并对文本进行规范化处理。
随后按多种标准过滤数据。常见的过滤模式包括:元数据(如 URL 或文件名)、内容(排除有毒内容或包含 PII 的内容)、语言、过度重复或垃圾内容、文档长度,以及使用正则表达式或简单的质量分类器。例如,你可以丢弃含有不良词汇或格式噪声很大的文本,或反过来只保留特定主题的文档。
过滤之后进行去重:采集到的数据集可能包含完全相同或几乎相同的文档(改写稿、重复的 HTML 页面等)。MinHash、SimHash 等算法可以识别完全重复与近似重复的内容并将其移除。这一点很重要,因为重复内容会拉低训练质量(模型会把重复文本“背下来”)。
训练前的最后一步是最终清理:内容分类(质量评估、移除有毒片段、处理 PII)。例如,会检查数据集中是否包含个人信息,并过滤不当内容,以确保模型安全与数据一致性。完成后,准备好的文本语料将进入训练阶段(分词、打包成批次等)。
基础设施与分布式训练
训练大型 LLM 通常需要由数百甚至数千张 GPU/TPU 组成的集群。受 GPU 显存与计算限制影响,会采用多种并行方式 – 张量并行(把模型层拆分到不同设备上)、流水线并行(不同层在不同设备上按顺序运行)、以及数据并行(每个设备保留完整模型副本,处理不同数据批次)。这种组合方式(如 NVIDIA Megatron-LM 所采用的方案)能将训练扩展到数千张 GPU。例如,Megatron-LM 曾在3,072 张 GPU上训练出1 万亿参数模型,实现超过 500 petaflops 的有效性能。这类系统通常依赖高速网络(InfiniBand)、大内存服务器,以及用于 checkpoint 存储的 SSD。
另一个关键组件是分区数据存储(数据湖或面向大数据优化的文件系统),抓取结果会存放在这里。通常会使用多层存储:冷存储(低频访问)与热存储(直接向训练管道供数)。集群监控系统(如 Prometheus/Grafana)同样不可或缺,用于追踪 GPU 利用率、训练速度、内存占用、功耗等指标。
训练架构示例:下面是一个简化示意图,展示各组件的交互方式:通过代理进行数据采集、数据转换与存储、以及训练集群。这只是众多可行设计中的一种。
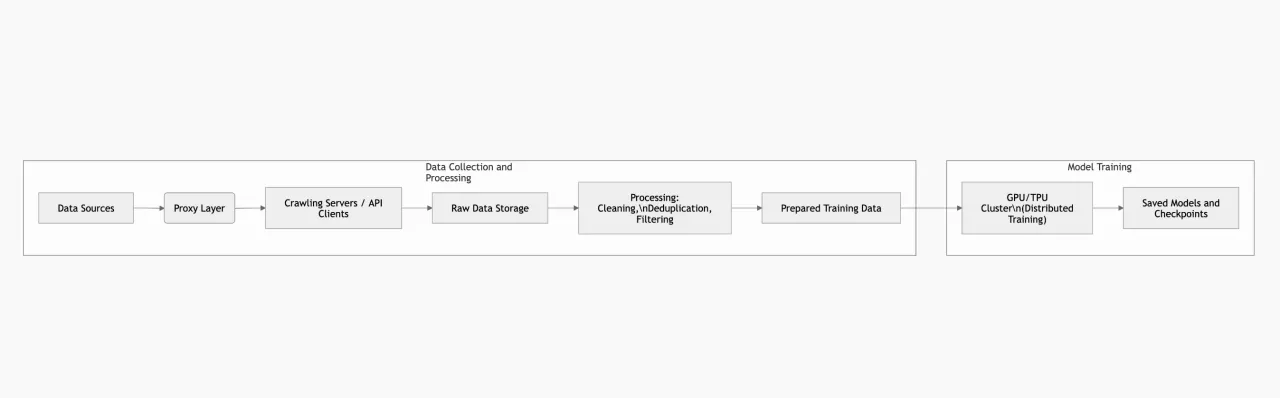
安全、隐私与合规
在处理 LLM 数据时,必须考虑伦理与法律要求,包括版权与个人数据保护、遵守许可条款与 GDPR,以及即将落地的 AI 监管(例如欧盟《AI 法案》要求透明度与数据质量控制)。使用代理并不意味着免责:数据集必须来自公开且允许使用的来源。
训练系统本身的安全也同样关键。集群需要防止未授权访问(网络防火墙、网络分段等),软件应定期更新,存储数据需要加密。安全监控(IDS/IPS、请求日志)能帮助发现基础设施中的异常行为。
代理服务器:类型与特性
主要代理类型
-
住宅代理 – 来自真实用户的 IP 地址。网站很少封禁,因此成功率通常在95–99%左右。如今,这被认为是 LLM 训练中最受欢迎的选择。 住宅代理适用于需要尽可能“像人”的流量场景(社交媒体、强防护网站、本地化页面)。此外,它支持精确到城市级的定位,这对某些任务很重要。
-
移动代理 – 来自移动运营商网络的 IP。由于同一 IP 往往会被大量用户同时共享,网站通常不会轻易封禁,因此它们比住宅代理更“匿名”。一般用于住宅代理效果不够,或需要模拟移动端用户的场景。
-
数据中心代理 – 托管在数据中心(AWS、Azure 等)的 IP。速度快、价格低、带宽高,但更容易被识别:数据中心网段常被安全系统直接拦截。在防护较强的网站上总体成功率约为40–60%,但延迟最低。适合从反爬较弱的网站进行大规模采集。
上述代理类型通常都需要结合“轮换代理”的视角来理解,不同之处在于 IP 更换频率。下面展开说明。
-
有些轮换代理会在每次请求后更换 IP,或按固定时间间隔更换。由于 IP 池可能包含数百万个地址并可随时调用,这类代理匿名性更强。适用于短促的“请求即走”型任务。
-
带固定 IP 的轮换代理 – 本质上仍是轮换代理,但 IP 不会每次请求都变化,而是尽可能长时间保持不变。它适合多步骤操作(登录、提交表单等),因为频繁换 IP 往往会触发重新验证。换句话说,sticky 代理会在整个会话期间维持同一个 IP,模拟真实用户会话;而标准轮换代理则为每个请求分配新 IP。两种方式可按任务需要组合使用。
代理性能与安全性
选择代理类型本质上是在速度与可靠性之间取舍。数据中心代理在吞吐量上领先(通常比住宅代理快 3–4 倍),但更容易被封。住宅代理能提供最高的访问质量(成功率约 99%),但响应时间更长。移动代理最昂贵也更慢,但信任度最高(运营商级网络)。
反爬系统通常会综合一串信号:IP、时序、请求头以及行为指纹。代理服务通过在不同 IP 与地理位置间分发流量,甚至控制请求时序以模拟自然延迟,从而缓解其中大部分风险。但同时,代理也无法保证百分百成功。如果系统识别出明显的自动化行为,仍可能触发验证码。
在数据采集中集成代理
在代码中接入代理池属于常规工作。例如在 Python 中使用 requests 库,可以这样配置代理:
import requests
proxies = {
"http": "http://user:pass@proxy.example.com:port",
"https": "https://user:pass@proxy.example.com:port",
}
response = requests.get("http://example.com", proxies=proxies)
对于长会话(例如需要认证的场景),可以使用 requests.Session() 并复用同一个代理,或在服务端指定 session_id 或 sticky 参数。在 Scrapy 这类框架中,有用于代理轮换的中间件:你提供一个 IP 列表,Scrapy 会自动轮换并控制请求速率。在浏览器自动化工具(Selenium、Playwright)中,代理通常通过浏览器参数传入(--proxy-server=http://host:port)。
还需要选择合适的鉴权方式。代理服务一般支持:
-
用户名:密码(Basic Auth)– HTTP/HTTPS 代理的标准方式(如上例)。
-
API key/token – 用于访问服务(通常通过 HTTP header 传递)。
-
IP 白名单 – 一些服务商允许将你的服务器加入白名单,从而无需鉴权即可使用代理。
数据采集的监控与优化
要让数据管道稳定运行,必须跟踪关键指标:
-
请求成功率: 返回有效数据而非错误(4xx/5xx)的请求占比。针对目标域名,理想值应高于 95%。
-
延迟: 平均响应时间,以及 p90、p99。住宅代理由于“最后一公里”因素,这些指标更高,但其延迟通常更稳定。
-
状态码: 按 host 与 ASN 统计 403/429 与 5xx 响应数量。某个 IP 池对特定站点的 403 突增,通常意味着该网段正在被封。
-
会话保持: 会话在无需重新登录的情况下能维持多久。该指标与 sticky 会话的使用高度相关。
-
吞吐量: 抓取时的 GB/sec,用于估算成本(GPU 时间往往比存储 20+ 份 HTML 页面副本更便宜)。也建议监控 5 分钟窗口内 TLS 握手成功率,接近 100% 通常意味着 IP 池健康。
任何数据采集系统都必须具备故障韧性:必要时返回空结果,采用退避策略重试,并为每个代理跟踪错误率。例如,可以限制每个 IP 在每个域名上的请求数,并根据 403/429 响应动态调整;遵循 Retry-After header;并替换已经“烧掉”的 IP。
面向 LLM 任务的五大代理服务商
下表对五家在 AI/LLM 工作负载语境中常被提及的代理服务商进行对比(依据住宅与移动资源池的可用性、可扩展性与数据采集能力)。每家服务商都列出代理类型、覆盖范围、鉴权方式、计费模式与反封锁特性。
| 服务商 | URL | 代理类型 | 地理覆盖 | 吞吐 / 延迟 | 鉴权方式 | 计费模式(住宅代理) | 反爬特性 | 优点 / 缺点 |
|---|---|---|---|---|---|---|---|---|
| NodeMaven | https://nodemaven.com/ | 住宅、移动 | 覆盖 150+ 国家,全球 1400+ 城市 | 高(干净 IP 与 sticky 会话) | 账号/密码、IP 白名单 | 按量付费与月度套餐($2.86-$6.18/GB) | sticky 会话最长 24 h,IP 质量过滤 | 优点:干净高质量 IP、sticky 会话、地理定向能力强。 缺点:价格可能高于一些低价替代方案。 |
| BrightData | https://brightdata.com/ | 住宅、数据中心、移动 | 覆盖 195+ 国家,全球资源池庞大 | 高(企业级)且 IP 网络规模大 | 账号/密码、API key | 按带宽计费(按量 $5–$8/GB,亦有更大月度包) | 高级验证码绕过与会话控制 | 优点:IP 池巨大,适合企业级需求,定向能力灵活。 缺点:计费较复杂,小规模使用成本偏高。 |
| ProxyScrape | https://proxyscrape.com/ | 数据中心、住宅 | 5500 万+ 住宅 IP,全球覆盖(195 个国家) | 中等(规模大但池子更通用) | API key,可能支持账号登录 | 灵活套餐($1.5-$4.85) | 基础 IP 轮换 | 优点:价格友好且选择灵活。 缺点:不同资源池与地区的质量波动较大。 |
| ProxyEmpire | https://proxyempire.io/ | 住宅、移动、数据中心 | 服务商宣称全球覆盖(数百万 IP) | 中高(优化的轮换资源池) | 账号/密码 | 按量付费(如 $3.5/GB 起)与小套餐 | IP 轮换与会话控制 | 优点:轮换策略可调,适合混合型工作负载。 缺点:资源池规模小于顶级企业服务商。 |
| DataImpulse | https://dataimpulse.com/ | 住宅、移动、数据中心 | 覆盖 100+ 国家,支持多区域 | 中等(网络稳定,性价比高) | 账号/密码 | 按量付费(住宅通常约 ~$1/GB) | 基础 IP 轮换 | 优点:非常便宜,代理类型齐全。 缺点:与巨头相比 IP 池更小。 |
关于价格的说明。 代理服务的价格差异很大:数据中心代理通常每 GB 只需不到 1 美元,而住宅与移动代理往往每 GB 需要数美元甚至更高。计费模式一般分为按带宽计费(按量/按 GB)或按 IP 订阅。对于大规模业务,采用混合模式往往更省钱(稳定会话用按 IP 计费,高并发抓取用按 GB 计费)。
监控与性能度量
为了保证数据质量与训练效率,建议跟踪以下指标:
-
数据质量: 有效、非空且未损坏结果的占比。对 LLM 来说,采集文本是否有意义且相关至关重要。
-
覆盖度: 收集到的页面/文档数量,以及覆盖广度(不同域名、语言与地区)。
-
采集速度: 每日文档量,包括通过代理请求的平均延迟。
-
训练指标: 训练完成后关注 perplexity、验证集准确率与损失函数趋势。优秀表现通常意味着数据管道工作正常。
-
代理指标: 成功率(重试与失败)、延迟分位数(p50/p90)、活跃会话数以及被封 IP 数量。
还建议监控握手成功率(TLS,接近 100% 通常代表 IP 健康)以及不同自治系统上的响应码分布(403/429)。成功率偏低(例如代理鉴权失败频繁)通常意味着连接质量不佳。
成本优化
即使预算不是硬约束,成本优化仍然重要:
-
按需求购买: 在按量付费与月付订阅之间做选择。月付通常更便宜,如果能预估用量,一般更划算。
-
平衡代理类型: 高优先级目标使用住宅代理,次要目标使用数据中心代理,以降低成本。
-
使用替代数据源: 可行时优先使用 scraper API 或现成数据集(如 Common Crawl、Wikipedia SQL dumps),减少抓取需求,从而显著降低代理消耗。
-
优化数据管道: 减少进入训练的数据量(去重、预过滤)以节省 GPU 资源。例如,你通过代理采集了 1 TB 数据,但去重后只剩 100 GB,那么等效节省了约 90% 的算力成本。
结语
LLM 训练是一项复杂工程,既需要强大的基础设施,也离不开设计良好的数据管道与专用工具。代理服务器在数据采集阶段扮演关键角色,它让系统具备可扩展性、数据多样性,并能持续为模型提供新鲜数据。选择合适的代理类型(住宅、数据中心、移动)以及工作模式(轮换与 sticky)对最终效果至关重要。
建议把 LLM 系统设计当作典型工程问题来处理:根据会话与可信度需求对数据流分层,为代理与数据健康建立监控体系,并持续迭代轮换与重试策略。使用高质量的代理服务商(如上表所列)可以显著提升抓取成功率。更重要的是,模型的真实成本不仅是 GPU 时间,还包括数据的完整性与质量。通过代理获取既快速又“像人”的访问模式,并在此基础上保持数据质量平衡,最终会明显提升训练结果。













