
En este artículo analizamos en detalle la arquitectura y la infraestructura para el entrenamiento de grandes modelos de lenguaje (LLM), con especial atención al papel de los servidores proxy en la recopilación de datos y en garantizar la escalabilidad. Los LLM se entrenan con volúmenes gigantescos de texto (por ejemplo, GPT-3, unas 300.000 millones de fichas ≈ 45 TB de texto), por lo que la canalización de datos incluye un procesamiento en varias etapas: rastreo, limpieza, deduplicación, filtrado, tokenización y entrenamiento distribuido. Los proxies son la base de esta canalización, ya que permiten la recolección de datos web a gran escala, ayudan a evitar bloqueos, controlan la geolocalización y distribuyen la carga de forma uniforme.
Cubriremos todas las etapas de la canalización de un LLM (desde la recopilación y preparación de datos hasta el entrenamiento distribuido, la seguridad, la monitorización y el despliegue), y mostraremos dónde y por qué deberían usarse proxies. También examinaremos por separado los tipos de proxy (residenciales, de centro de datos, móviles), así como su rendimiento y casos de uso prácticos. Además, compararemos en una tabla cinco proveedores de proxy líderes para tareas relacionadas con LLM.
No tienes tiempo para leer? NodeMaven es el mejor proveedor de proxies para entrenar LLM.
Etapas de la canalización de datos de un LLM
El entrenamiento de un LLM comienza construyendo un gran corpus de datos textuales a partir de fuentes diversas: Common Crawl, sitios web, enciclopedias, artículos de investigación, libros, repositorios de código y más. Sin embargo, no basta con tomar toda la web: los datos deben ser recientes, variados y de alta calidad. Por eso muchos laboratorios ejecutan un rastreo continuo de nuevas páginas para que los modelos se mantengan actualizados (de lo contrario, un modelo como GPT-4 entrenado con datos hasta 2021 no podrá responder preguntas sobre acontecimientos de 2025).
La canalización de procesamiento de datos para LLM incluye los siguientes pasos clave:
-
Rastreo – descarga de HTML/JSON/medios en bruto a través de la red;
-
Limpieza – eliminación de plantillas HTML, anuncios y scripts;
-
Deduplicación – eliminación de documentos idénticos y casi duplicados;
-
Filtrado – selección por calidad, exclusión de contenido tóxico o personal, idiomas, etc.;
-
Entrenamiento – tokenización y entrenamiento en clústeres de GPU/TPU. Todas estas etapas requieren una infraestructura bien diseñada y monitorización.
A continuación se muestra un diagrama ilustrativo de esta canalización (con énfasis en el papel de los proxies):
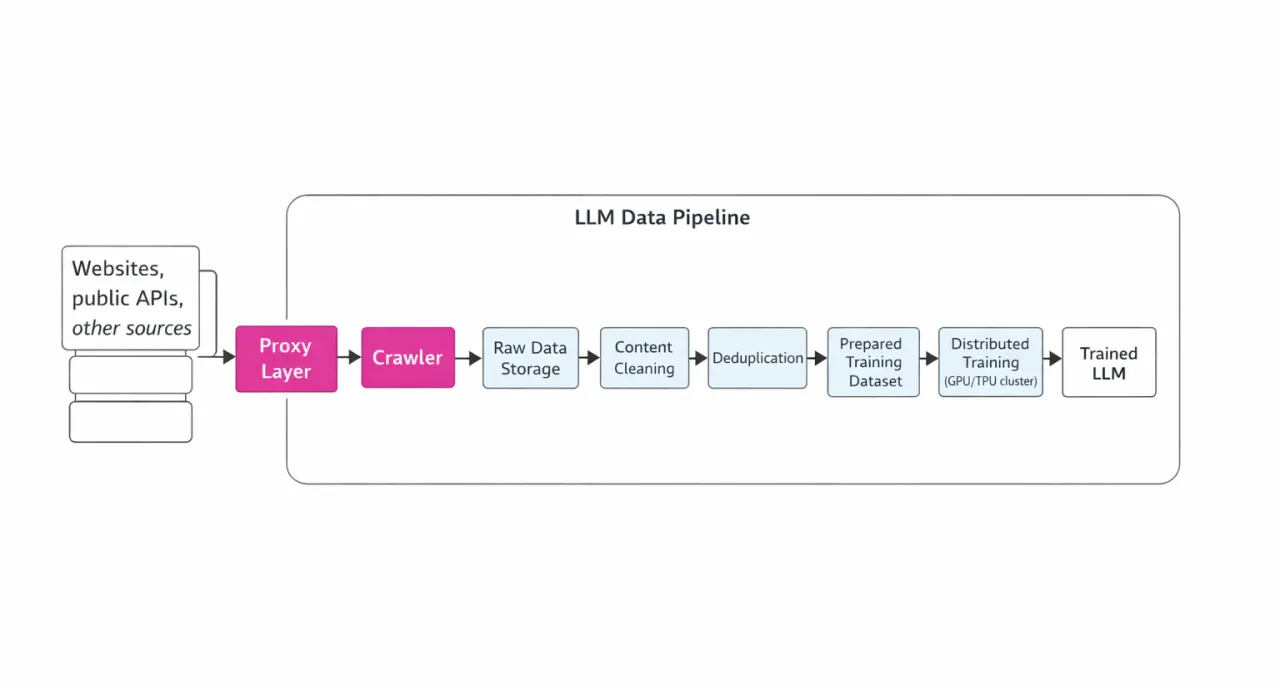
Rastreo y el papel de los proxies
Durante el rastreo es necesario enviar millones de solicitudes HTTP(S) de forma simultánea a distintos sitios web. Sin embargo, las protecciones antibot y los límites basados en IP suelen bloquear las campañas de scraping a gran escala. Ahí es donde entran en juego los servidores proxy. Los proxies permiten repartir las solicitudes entre miles de direcciones IP y ubicaciones geográficas, lo que reduce notablemente la probabilidad de bloqueo. Los proxies rotatorios son especialmente importantes, ya que permiten una recopilación continua de datos sin interrupciones. También ayudan a simular solicitudes de usuarios reales y a evitar la detección. Incluso al acceder a APIs (por ejemplo, de otros servicios o al generar datos sintéticos con LLM), los proxies ayudan a distribuir la carga y a respetar los límites de velocidad.
No obstante, conviene subrayarlo: los proxies resuelven limitaciones técnicas (bloqueos por IP, rate limits, localización), pero no se saltan restricciones legales. Usar proxies no elimina la obligación de cumplir robots.txt y la normativa aplicable, así que, incluso con proxies, debes respetar las reglas del sitio y los requisitos legales al recopilar datos.
Procesamiento de datos (limpieza, filtrado, deduplicación)
Tras recopilar el contenido en bruto, comienza la fase de preprocesamiento. Por ejemplo, AWS describe que "el primer paso de la canalización consiste en extraer y reunir datos de diversas fuentes y formatos (PDF, HTML, JSON, documentos de Office)", usando OCR, parsers HTML y herramientas similares. En esta etapa se eliminan elementos no deseados (etiquetas HTML, caracteres no ingleses) y se normaliza el texto.
Después, los datos se filtran según distintos criterios. Entre los patrones de filtrado recomendados se incluyen metadatos (como la URL o el nombre del archivo), contenido (excluyendo contenido tóxico o PII), idioma, repetición excesiva o spam, longitud del documento, así como el uso de expresiones regulares o clasificadores simples de calidad. Por ejemplo, podrías descartar textos con vocabulario indeseable o formatos ruidosos, o, por el contrario, conservar solo documentos sobre temas concretos.
Tras el filtrado se realiza la deduplicación: el conjunto de datos recopilado puede contener documentos idénticos o casi idénticos (reescrituras, páginas HTML duplicadas, etc.). Algoritmos como MinHash o SimHash permiten detectar copias exactas y casi duplicadas y eliminarlas. Esto es importante porque los duplicados degradan la calidad del entrenamiento (el modelo simplemente "memoriza" texto repetido).
El último paso antes del entrenamiento es la limpieza final: clasificación del contenido (evaluación de calidad, eliminación de fragmentos tóxicos, PII). Por ejemplo, se revisan los datasets en busca de datos personales y se filtra el contenido inapropiado, garantizando la seguridad del modelo y la consistencia de los datos. Después, el corpus de texto preparado pasa a la fase de entrenamiento (tokenización, creación de lotes, etc.).
Infraestructura y entrenamiento distribuido
Entrenar un LLM grande requiere clústeres con cientos o incluso miles de GPU/TPU. Debido a las limitaciones de memoria y cómputo de las GPU, se usan distintos tipos de paralelismo: paralelismo de tensores (dividir las capas del modelo entre dispositivos), paralelismo por canalización (capas diferentes se ejecutan secuencialmente en dispositivos distintos) y paralelismo de datos (una copia completa del modelo en cada dispositivo, procesando lotes de datos diferentes). Esta combinación (como la que utiliza NVIDIA Megatron-LM) permite escalar el entrenamiento a miles de GPU. Por ejemplo, Megatron-LM entrenó un modelo con 1 billón de parámetros en 3.072 GPU. El resultado supera los 500 petaflops de rendimiento efectivo. Estos sistemas suelen apoyarse en redes de alta velocidad (InfiniBand), servidores con mucha memoria y SSD para almacenar checkpoints.
Un componente clave es el almacenamiento de datos particionado (Data Lakes o sistemas de archivos optimizados para big data), donde se guardan los resultados del rastreo. Normalmente se emplean varios niveles de almacenamiento: almacenamiento frío (acceso menos frecuente) y almacenamiento caliente (alimenta directamente la canalización de entrenamiento). Los sistemas de monitorización del clúster (por ejemplo, Prometheus/Grafana) también son esenciales para seguir el uso de GPU, la velocidad de entrenamiento, el consumo de memoria, el gasto energético y más.
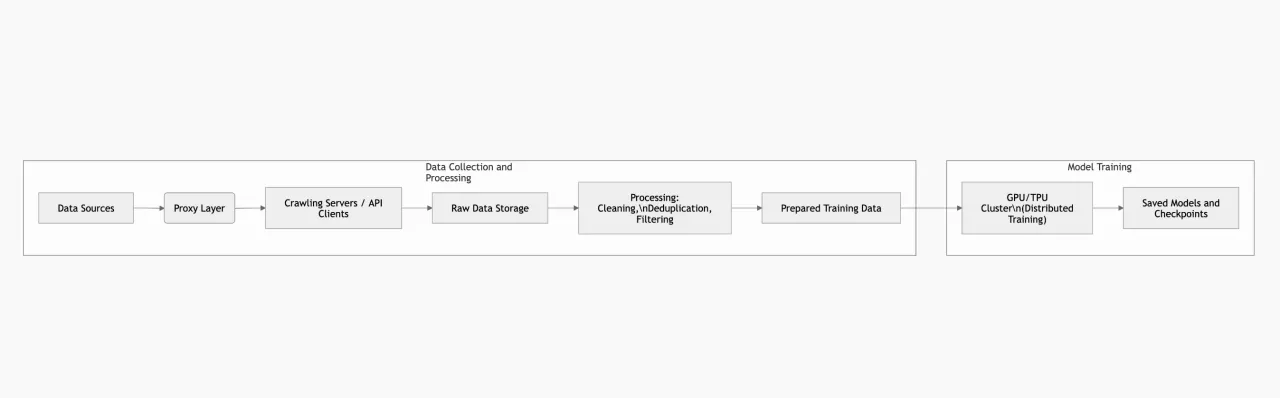
Ejemplo de una arquitectura de entrenamiento: A continuación se muestra un diagrama simplificado que ilustra cómo interactúan los componentes: recopilación de datos mediante proxies, transformación y almacenamiento de datos, y clústeres de entrenamiento. Es solo una de las posibles aproximaciones de diseño.
Seguridad, privacidad y cumplimiento
Al trabajar con datos para LLM es importante considerar requisitos éticos y legales. Esto incluye proteger derechos de autor y datos personales, cumplir restricciones de licencias y el GDPR, así como las próximas normativas de IA (por ejemplo, el EU AI Act exige transparencia y control de calidad de los datos). Usar proxies no elimina la responsabilidad: los datasets deben construirse a partir de fuentes públicas y permitidas.
La seguridad del propio sistema de entrenamiento también es crítica. Los clústeres deben protegerse frente a accesos no autorizados (firewalls de red, segmentación), el software debe actualizarse con regularidad y los datos almacenados deben cifrarse. La monitorización de seguridad (IDS/IPS, registro de solicitudes) ayuda a detectar anomalías en la infraestructura.
Servidores proxy: tipos y características
Principales tipos de proxy
-
Proxies residenciales – direcciones IP de usuarios reales. Los sitios web rara vez los bloquean, así que su tasa de éxito suele rondar el 95–99%. Hoy se considera la opción más popular para el entrenamiento de LLM. Los proxies residenciales son ideales cuando se requiere un tráfico lo más "humano" posible (redes sociales, sitios protegidos, versiones localizadas). Además, permiten segmentación a nivel de ciudad, lo que puede ser importante para ciertas tareas.
-
Proxies móviles – proxies con direcciones IP de operadores móviles. Son incluso más anónimos que los residenciales, ya que los sitios web rara vez los bloquean debido a que varios usuarios comparten la misma IP al mismo tiempo. Se usan normalmente cuando los proxies residenciales no bastan o cuando necesitas emular a un usuario móvil.
-
Proxies de centro de datos – direcciones IP alojadas en centros de datos (AWS, Azure, etc.). Son rápidos, baratos y ofrecen un gran ancho de banda. Sin embargo, son fáciles de detectar: las subredes de centros de datos suelen estar bloqueadas por sistemas de seguridad. En conjunto, la tasa de éxito en sitios protegidos está en torno al 40–60%, pero la latencia es mínima. Este tipo es adecuado para recopilar datos a gran escala de sitios con poca protección antibot.
Todos estos tipos de proxy suelen analizarse en el contexto de proxies rotatorios, que pueden diferir en la frecuencia con la que cambia la dirección IP. Veámoslo con más detalle.
-
Existen proxies rotatorios que cambian la IP después de cada solicitud o en un intervalo de tiempo definido. Estos proxies ofrecen un alto anonimato, ya que el pool de IP puede incluir millones de direcciones disponibles. Son útiles para solicitudes cortas de tipo "pedir y olvidar".
-
Proxies rotatorios con IP fija – en esencia son los mismos proxies rotatorios, pero la dirección IP no cambia en cada solicitud. En su lugar, se mantiene igual durante el mayor tiempo posible. Son ideales para operaciones de varios pasos (inicios de sesión, formularios, etc.), donde cambiar la IP dispararía una nueva autenticación. En otras palabras, los proxies sticky mantienen una sola IP durante toda la sesión, simulando una sesión de usuario real, mientras que los rotatorios estándar asignan una IP nueva a cada solicitud. Ambos enfoques pueden combinarse según la tarea.
Rendimiento y seguridad de los proxies
Elegir un tipo de proxy siempre es un equilibrio entre velocidad y fiabilidad. Los proxies de centro de datos lideran en throughput (son 3 a 4 veces más rápidos que los residenciales), pero se bloquean con más frecuencia. Los proxies residenciales pueden ofrecer la mayor calidad de acceso (una tasa de éxito cercana al 99%), pero con tiempos de respuesta más altos. Los proxies móviles son los más caros y más lentos, pero ofrecen el mayor nivel de confianza (redes de operadores).
Los sistemas antibot se basan en una cadena de señales: IP, tiempos, headers y huella conductual. Un servicio de proxies mitiga gran parte de esto al distribuir el tráfico entre IP y ubicaciones, e incluso al gestionar el timing de las solicitudes para simular retrasos naturales. Aun así, los proxies no garantizan un éxito perfecto. Si el sistema detecta un comportamiento claramente automatizado, la protección antibot puede seguir activando CAPTCHAs.
Integración de proxies en la recopilación de datos
Implementar un pool de proxies en el código es una tarea estándar. Por ejemplo, en Python usando la librería requests puedes configurar proxies así:
import requests
proxies = {
"http": "http://user:pass@proxy.example.com:port",
"https": "https://user:pass@proxy.example.com:port",
}
response = requests.get("http://example.com", proxies=proxies)
Para sesiones largas (por ejemplo, con autenticación), puedes usar requests.Session() y reutilizar el mismo proxy, o especificar un parámetro session_id o sticky a nivel de servicio. En frameworks como Scrapy existe middleware para rotación de proxies: proporcionas una lista de IP y Scrapy las recorre automáticamente controlando las tasas de solicitud. En herramientas de automatización de navegador (Selenium, Playwright), los proxies se pasan mediante la configuración del navegador (--proxy-server=http://host:port).
Es importante elegir el modelo de autenticación adecuado. Los servicios de proxies suelen admitir:
-
Usuario:contraseña (Basic Auth) – el estándar para proxies HTTP/HTTPS (como se muestra arriba).
-
Clave/token de API – se usa para acceder a servicios (a menudo mediante headers HTTP).
-
Allowlisting de IP – algunos proveedores permiten añadir tus servidores a una lista blanca para usar proxies sin autenticación.
Monitorización y optimización de la recopilación de datos
Para garantizar una canalización de datos estable, es importante seguir métricas clave:
-
Tasa de éxito de solicitudes: porcentaje de solicitudes que devuelven datos válidos en lugar de errores (4xx/5xx). Idealmente, debería estar por encima del 95% para los dominios objetivo.
-
Latencia: tiempo medio de respuesta, así como p90 y p99. En proxies residenciales estos valores son más altos por el factor de última milla, pero suelen presentar una latencia más estable.
-
Códigos de estado: monitoriza la cantidad de respuestas 403/429 y 5xx por host y ASN. Un aumento repentino de errores 403 en un pool de IP concreto suele indicar que se está bloqueando la subred.
-
Retención de sesión: cuánto tiempo permanecen activas las sesiones sin exigir un nuevo inicio de sesión. Esta métrica está estrechamente relacionada con el uso de sesiones sticky.
-
Throughput: GB/seg durante el rastreo, importante para estimar costes (el tiempo de GPU suele ser más barato que almacenar más de 20 copias de páginas HTML). También se recomienda supervisar las tasas de éxito de handshake TLS en intervalos de 5 minutos: cerca del 100% indica un pool de IP saludable.
Cualquier sistema de recopilación de datos debe ser resistente a fallos: devolver resultados vacíos cuando sea necesario, reintentar solicitudes con backoff y seguir las tasas de error por proxy. Por ejemplo, puedes limitar el número de solicitudes por IP y por dominio y ajustar según las respuestas 403/429, respetar los headers Retry-After y sustituir IP "quemadas".
Top 5 proveedores de proxy para tareas con LLM
A continuación se muestra una tabla comparativa de cinco proveedores de proxy que suelen mencionarse en el contexto de cargas de trabajo de IA/LLM (según la disponibilidad de pools residenciales y móviles, la escalabilidad y las capacidades de recopilación de datos). Para cada proveedor incluimos tipos de proxy, cobertura geográfica, métodos de autenticación, modelo de precios y funciones antibloqueo.
| Proveedor | URL | Tipos de proxy | Cobertura geográfica | Throughput / latencia | Métodos de autenticación | Modelo de precios (Proxies residenciales) | Funciones antibot | Pros / Contras |
|---|---|---|---|---|---|---|---|---|
| NodeMaven | https://nodemaven.com/ | Residencial, móvil | 150+ países, 1400+ ciudades a nivel mundial | Alto (IP limpias y sesiones sticky) | Usuario/contraseña, lista blanca de IP | Pago por uso y planes mensuales ($2.86-$6.18/GB) | Sesiones sticky hasta 24 h, filtro de calidad de IP | Pros: IP limpias de alta calidad, sesiones sticky, segmentación geográfica. Contras: el precio puede ser más alto que el de alternativas económicas. |
| BrightData | https://brightdata.com/ | Residencial, centro de datos, móvil | 195+ países, amplio pool global | Alto (nivel empresarial) con gran red de IP | Usuario/contraseña, claves API | Precios por ancho de banda ($5–$8/GB pago por uso, paquetes mensuales mayores) | Bypass avanzado de CAPTCHA y control de sesión | Pros: pool de IP enorme, ideal para empresas, segmentación flexible. Contras: precios complejos, caro para uso pequeño. |
| ProxyScrape | https://proxyscrape.com/ | Centro de datos, residencial | 55M+ IP residenciales, cobertura global (195 países) | Medio (pool grande pero más genérico) | Claves API, posibles credenciales de acceso | Planes flexibles ($1.5-$4.85) | Rotación básica de IP | Pros: asequible y flexible. Contras: la calidad varía según el pool y la región. |
| ProxyEmpire | https://proxyempire.io/ | Residencial, móvil, centro de datos | Cobertura global (millones de IP) según el proveedor | Medio-alto (pools rotatorios optimizados) | Usuario/contraseña | Pago por uso (p. ej., desde $3.5/GB) y planes pequeños | IP rotatorias y controles de sesión | Pros: ajustes de rotación flexibles, bueno para cargas mixtas. Contras: pool más pequeño que el de proveedores empresariales de primer nivel. |
| DataImpulse | https://dataimpulse.com/ | Residencial, móvil, centro de datos | 100+ países, soporte multirregión | Medio (red sólida, asequible) | Usuario/contraseña | Pago por uso (a menudo ~ $1/GB residencial) | Rotación básica de IP | Pros: muy asequible, múltiples tipos de proxy. Contras: pool de IP más pequeño en comparación con los gigantes. |
Nota sobre los precios. Los precios de los servicios de proxies pueden variar de forma considerable: los proxies de centro de datos suelen costar fracciones de dólar por GB, mientras que los proxies residenciales y móviles pueden costar varios dólares o más por GB. Los modelos de precios suelen ser por ancho de banda (pago por uso/GB) o suscripciones por IP. Para operaciones a gran escala, a menudo resulta más rentable usar un modelo híbrido (basado en IP para sesiones estables y basado en GB para solicitudes de alto volumen).
Monitorización y medición del rendimiento
Para garantizar la calidad de los datos y la eficiencia del entrenamiento, deben seguirse las siguientes métricas:
-
Calidad de datos: porcentaje de resultados válidos, no vacíos y no corruptos. Para los LLM es fundamental que el texto recopilado sea significativo y relevante.
-
Cobertura: número de páginas/documentos recopilados y amplitud de cobertura (distintos dominios, idiomas, regiones).
-
Velocidad de recopilación: documentos por día, incluida la latencia media de solicitudes a través de proxies.
-
Métricas de entrenamiento: después del entrenamiento: perplejidad, precisión de validación y tendencias de la función de pérdida. Unos resultados sólidos indican que la canalización de datos está funcionando correctamente.
-
Métricas de proxy: tasa de éxito (reintentos y fallos), percentiles de latencia (p50/p90), número de sesiones activas e IP bloqueadas.
También se recomienda monitorizar el Handshake Success Rate (TLS; cerca del 100% indica IP saludables) y la distribución de códigos de respuesta (403/429) entre Sistemas Autónomos. Una menor tasa de éxito (por ejemplo, fallos frecuentes de autenticación del proxy) indica mala calidad de conexión.
Optimización de costes
Incluso sin restricciones presupuestarias estrictas, es importante optimizar costes:
-
Comprar según las necesidades: elige entre pago por uso o modelos de suscripción mensual. Los planes mensuales suelen ser más baratos, así que si conoces tu consumo esperado, por lo general son más rentables.
-
Equilibrar tipos de proxy: asigna objetivos de alta prioridad a proxies residenciales y los menos críticos a proxies de centro de datos para reducir costes.
-
Usar fuentes alternativas de datos: cuando sea posible, apóyate en APIs de scraping o datasets existentes (p. ej., Common Crawl, volcados SQL de Wikipedia) para reducir la necesidad de scraping. Esto puede reducir de forma notable el uso de proxies.
-
Optimizar la canalización de datos: reduce la cantidad de datos que entra al entrenamiento (deduplicación, prefiltrado) para ahorrar recursos de GPU. Por ejemplo, si recopilas 1 TB de datos mediante proxies pero tras deduplicar solo quedan 100 GB, en la práctica ahorras alrededor del 90% de los costes de cómputo.
Conclusión
Entrenar LLM es un proceso complejo que exige una infraestructura potente, una canalización de datos bien diseñada y herramientas especializadas. Los servidores proxy cumplen un papel crucial en la fase de recopilación de datos al permitir escalabilidad, diversidad y un flujo continuo de datos recientes hacia el modelo. Elegir los tipos de proxy adecuados (residenciales, de centro de datos, móviles) y los modos (rotatorio frente a sticky) es determinante para el éxito.
Recomendamos abordar el diseño de sistemas LLM como un problema de ingeniería: segmenta los flujos de datos según los requisitos de sesión y confianza, implementa monitorización de la salud de proxies y datos, y mejora de forma iterativa las estrategias de rotación y reintentos. Usar proveedores de proxy de alta calidad (como los listados arriba) garantizará una alta tasa de éxito en el rastreo. Y, sobre todo, recuerda que el coste real de un modelo no es solo el tiempo de GPU, sino también la integridad y la calidad de los datos. Una combinación equilibrada de acceso rápido y patrones de tráfico "humanos" recopilados mediante proxies mejorará de forma significativa los resultados finales del entrenamiento.



















