
В этой статье мы подробно разберем архитектуру и инфраструктуру обучения больших языковых моделей (LLM), уделив особое внимание роли прокси серверов в сборе данных и обеспечении масштабируемости. LLM обучаются на колоссальных объемах текста (например, GPT-3: около 300 млрд токенов ≈ 45 ТБ текста), поэтому конвейер данных включает многоэтапную обработку: краулинг, очистку, дедупликацию, фильтрацию, токенизацию и распределенное обучение. Прокси лежат в основе этого процесса: они позволяют собирать веб данные в больших масштабах, помогают избегать блокировок, управлять геолокацией и равномерно распределять нагрузку.
Мы рассмотрим все этапы конвейера LLM (от сбора и подготовки данных до распределенного обучения, безопасности, мониторинга и развертывания) и покажем, где и почему стоит использовать прокси. Отдельно разберем типы прокси (резидентные, датацентровые, мобильные), а также их производительность и практические сценарии применения. Кроме того, в таблице сравним пять ведущих провайдеров прокси для задач, связанных с LLM.
Нет времени читать? NodeMaven — лучший прокси провайдер для обучения LLM.
Этапы конвейера данных для LLM
Обучение LLM начинается с построения большого текстового корпуса из разнообразных источников: Common Crawl, сайтов, энциклопедий, научных статей, книг, репозиториев кода и многого другого. Однако просто взять весь веб недостаточно: данные должны быть актуальными, разнообразными и качественными. Поэтому многие лаборатории запускают непрерывный краулинг новых страниц, чтобы модели оставались в курсе событий (иначе модель уровня GPT-4, обученная на данных до 2021 года, не сможет отвечать на вопросы о событиях 2025 года).
Конвейер обработки данных для LLM включает следующие ключевые шаги:
-
Crawling — скачивание сырого HTML/JSON/медиа по сети;
-
Cleaning — удаление HTML шаблонов, рекламы и скриптов;
-
Deduplication — удаление точных и близких дублей документов;
-
Filtering — отбор по качеству, исключение токсичного или персонального контента, языков и т. д.;
-
Training — токенизация и обучение на кластерах GPU/TPU. Все эти этапы требуют продуманной инфраструктуры и мониторинга.
Ниже приведена наглядная схема этого конвейера (с акцентом на роль прокси):
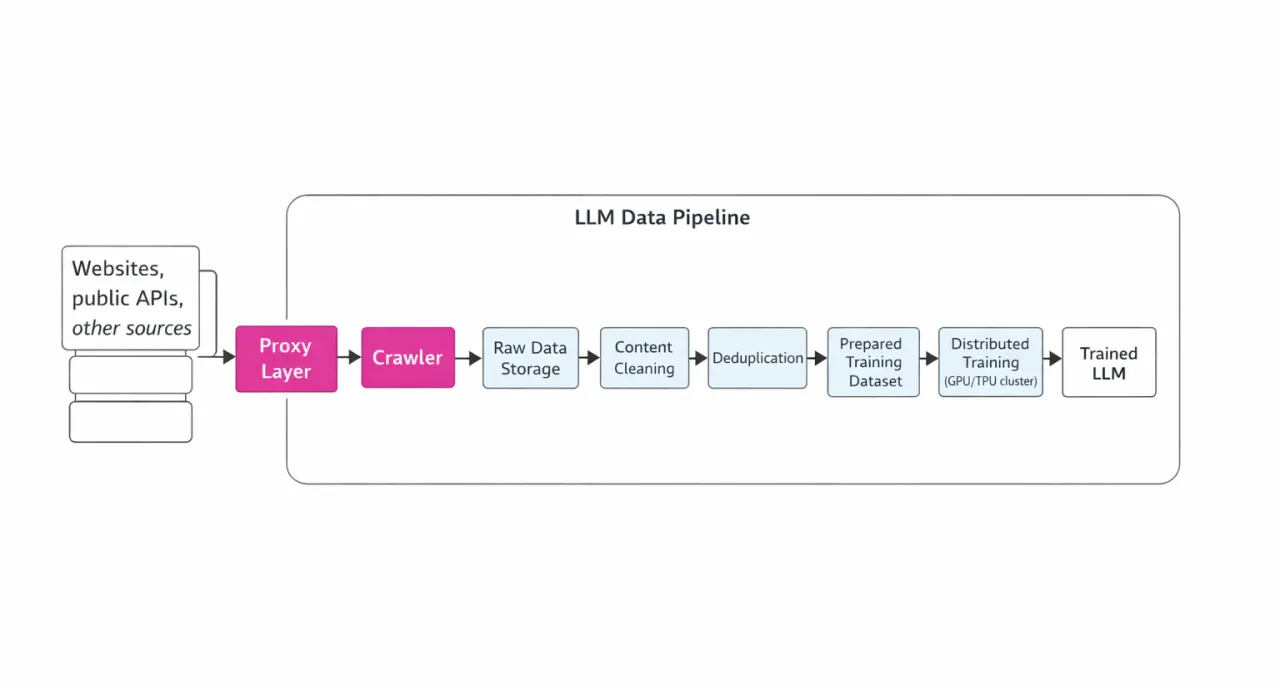
Краулинг и роль прокси
Во время краулинга необходимо одновременно отправлять миллионы HTTP(S) запросов на разные сайты. Однако антибот защита и ограничения по IP часто блокируют масштабные кампании по сбору данных. Здесь и вступают в дело прокси серверы. Прокси позволяют распределять запросы по тысячам IP адресов и геолокаций, заметно снижая вероятность блокировок. Особенно важны ротационные прокси: они дают возможность собирать данные непрерывно, без простоев. Прокси также помогают имитировать запросы реальных пользователей и снижать риск детекта. Даже при доступе к API (например, к сторонним сервисам или при генерации синтетических данных с помощью LLM) прокси помогают распределять нагрузку и укладываться в rate limits.
Однако важно понимать: прокси решают технические ограничения (блокировки по IP, лимиты частоты запросов, локализация), но не обходят юридические запреты. Использование прокси не отменяет необходимости соблюдать robots.txt и применимое законодательство, поэтому даже при работе через прокси следует уважать правила сайтов и правовые требования при сборе данных.
Обработка данных (очистка, фильтрация, дедупликация)
После сбора сырого контента начинается этап препроцессинга. Например, AWS описывает, что "первый шаг в конвейере — извлечь и собрать данные из разных источников и форматов (PDF, HTML, JSON, документы Office)", используя OCR, HTML парсеры и похожие инструменты. На этом этапе удаляются лишние элементы (HTML теги, неанглийские символы) и нормализуется текст.
Далее данные фильтруются по различным критериям. Среди рекомендуемых подходов к фильтрации: метаданные (например URL или имя файла), контент (исключение токсичного или PII контента), язык, чрезмерные повторы или спам, длина документа, а также применение регулярных выражений или простых классификаторов качества. Например, можно отбрасывать тексты с нежелательной лексикой или "шумными" форматами или, наоборот, оставлять только документы по конкретным темам.
После фильтрации выполняется дедупликация: в собранном датасете могут встречаться одинаковые или почти одинаковые документы (рерайты, дубликаты HTML страниц и т. п.). Алгоритмы вроде MinHash или SimHash позволяют обнаруживать точные и почти совпадающие копии и удалять их. Это важно, потому что дубли ухудшают качество обучения (модель просто "запоминает" повторяющийся текст).
Финальный шаг перед обучением — окончательная очистка: классификация контента (оценка качества, удаление токсичных фрагментов, PII). Например, датасеты проверяются на наличие персональных данных и неподходящий контент отфильтровывается, что повышает безопасность модели и согласованность данных. После этого подготовленный корпус передается на этап обучения (токенизация, батчинг и т. д.).
Инфраструктура и распределенное обучение
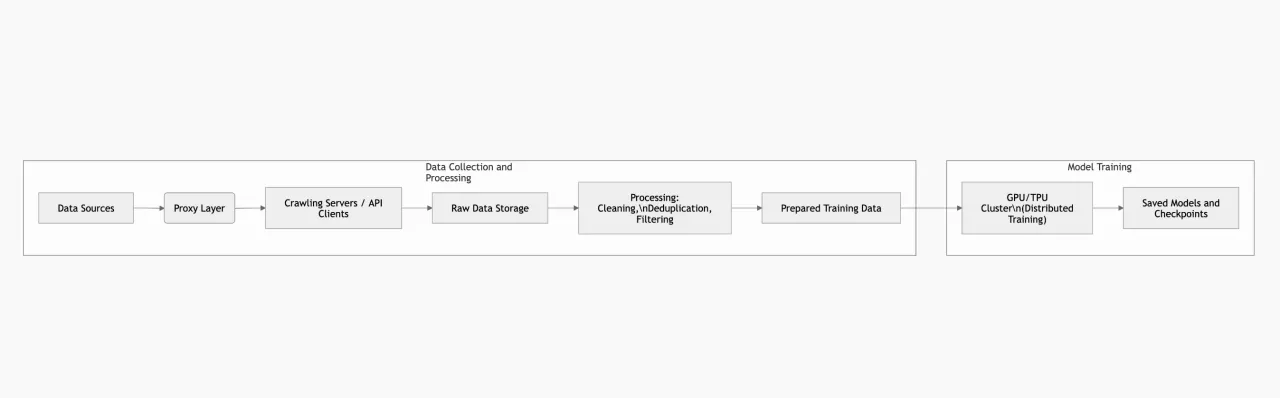
Обучение большой LLM требует кластеров с сотнями или даже тысячами GPU/TPU. Из-за ограничений памяти и вычислений на GPU используются разные виды параллелизма: tensor parallelism (разделение слоев модели между устройствами), pipeline parallelism (разные слои выполняются на разных устройствах последовательно) и data parallelism (полная копия модели на каждом устройстве, но разные батчи данных). Такая комбинация (как в NVIDIA Megatron-LM) позволяет масштабировать обучение до тысяч GPU. Например, Megatron-LM обучал модель с 1 триллионом параметров на 3 072 GPU. Итог — более 500 петафлопс эффективной производительности. Подобные системы обычно опираются на высокоскоростные сети (InfiniBand), серверы с большим объемом памяти и SSD для хранения чекпойнтов.
Ключевой компонент — разделенное хранение данных (Data Lakes или файловые системы, оптимизированные под big data) — именно там сохраняются результаты краулинга. Обычно используют несколько уровней хранения: холодное (к которому обращаются редко) и горячее (которое напрямую питает обучающий конвейер). Системы мониторинга кластера (например, Prometheus/Grafana) также необходимы для отслеживания загрузки GPU, скорости обучения, потребления памяти, энергопотребления и других метрик.
Пример архитектуры обучения: ниже показана упрощенная схема взаимодействия компонентов: сбор данных через прокси, преобразование и хранение данных, а также обучающие кластеры. Это лишь один из возможных вариантов проектирования.
Безопасность, приватность и соответствие требованиям
При работе с данными для LLM важно учитывать этические и юридические требования. Это включает защиту авторских прав и персональных данных, соблюдение лицензионных ограничений и GDPR, а также будущих норм регулирования ИИ (например, EU AI Act требует прозрачности и контроля качества данных). Использование прокси не снимает ответственности: датасеты должны собираться из публично доступных и разрешенных источников.
Критична и безопасность самой системы обучения. Кластеры нужно защищать от несанкционированного доступа (сетевые firewall, сегментация), ПО следует регулярно обновлять, а хранимые данные — шифровать. Мониторинг безопасности (IDS/IPS, логирование запросов) помогает выявлять аномалии в инфраструктуре.
Прокси серверы: типы и характеристики
Основные типы прокси
-
Резидентные прокси — IP адреса реальных пользователей. Сайты редко их блокируют, поэтому процент успешных запросов обычно составляет 95–99%. Сегодня это считается самым популярным вариантом для обучения LLM. Резидентные прокси идеально подходят там, где нужен максимально "человеческий" трафик (соцсети, защищенные сайты, локализованные версии). Кроме того, они позволяют таргетироваться на уровне города, что может быть важным для некоторых задач.
-
Мобильные прокси — прокси с IP адресами мобильных операторов. Они еще более "доверенные", чем резидентные, поскольку сайты редко блокируют их из-за того, что один и тот же IP одновременно разделяют многие пользователи. Обычно их используют, когда резидентных прокси недостаточно или когда нужно эмулировать мобильного пользователя.
-
Датацентровые прокси — IP адреса, размещенные в дата центрах (AWS, Azure и т. д.). Они быстрые, недорогие и обеспечивают высокую пропускную способность. Но их легко распознать: подсети дата центров часто блокируются системами безопасности. В целом успешность на защищенных сайтах составляет около 40–60%, зато задержка минимальна. Этот тип подходит для массового сбора данных с сайтов со слабой антибот защитой.
Все эти типы прокси обычно рассматривают в контексте ротации, которая может различаться по тому, как часто меняется IP адрес. Рассмотрим подробнее.
-
Есть ротационные прокси, которые меняют IP после каждого запроса или через заданный интервал времени. Они обеспечивают высокую анонимность, поскольку пул IP может включать миллионы адресов, доступных для использования. Это удобно для коротких запросов в стиле "fetch-and-forget".
-
Ротационные прокси с фиксированным IP — по сути те же ротационные прокси, но IP адрес не меняется на каждый запрос. Вместо этого он сохраняется максимально долго. Они идеально подходят для многошаговых операций (логины, формы и т. п.), где смена IP провоцирует повторную авторизацию. Иными словами, sticky прокси удерживают один IP на всю сессию, имитируя сессию реального пользователя, а стандартные ротационные прокси выдают новый IP на каждый запрос. Оба подхода можно комбинировать в зависимости от задачи.
Производительность и безопасность прокси
Выбор типа прокси всегда связан с компромиссом между скоростью и надежностью. Датацентровые прокси лидируют по пропускной способности (они в 3–4 раза быстрее резидентных), но чаще блокируются. Резидентные прокси дают самое высокое качество доступа (около 99% успешности), но с большей задержкой отклика. Мобильные прокси самые дорогие и более медленные, но обеспечивают максимальный уровень доверия (сети уровня операторов связи).
Антибот системы опираются на цепочку сигналов: IP, тайминги, заголовки и поведенческие отпечатки. Прокси сервис снижает влияние большинства из них, распределяя трафик по IP и геолокациям и даже управляя таймингом запросов, чтобы имитировать естественные задержки. При этом прокси не гарантируют абсолютного успеха. Если система видит явно автоматизированное поведение, антибот защита все равно может включить CAPTCHA.
Интеграция прокси в сбор данных
Реализация пула прокси в коде — стандартная задача. Например, в Python с использованием библиотеки requests можно настроить прокси так:
import requests
proxies = {
"http": "http://user:pass@proxy.example.com:port",
"https": "https://user:pass@proxy.example.com:port",
}
response = requests.get("http://example.com", proxies=proxies)
Для длинных сессий (например, с авторизацией) можно использовать requests.Session() и переиспользовать один и тот же прокси или указывать параметр session_id или sticky на уровне сервиса. В фреймворках вроде Scrapy есть middleware для ротации прокси: вы задаете список IP, и Scrapy автоматически перебирает их, одновременно контролируя частоту запросов. В инструментах браузерной автоматизации (Selenium, Playwright) прокси передаются через настройки браузера (--proxy-server=http://host:port).
Важно выбрать правильную модель аутентификации. Прокси сервисы обычно поддерживают:
-
Username:password (Basic Auth) — стандарт для HTTP/HTTPS прокси (как показано выше).
-
API key/token — используется для доступа к сервисам (часто через HTTP заголовки).
-
IP allowlisting — некоторые провайдеры позволяют добавить ваши серверы в белый список, чтобы прокси работали без аутентификации.
Мониторинг и оптимизация сбора данных
Чтобы обеспечить стабильность конвейера данных, важно отслеживать ключевые метрики:
-
Request Success Rate: доля запросов, которые возвращают валидные данные вместо ошибок (4xx/5xx). В идеале для целевых доменов она должна быть выше 95%.
-
Latency: среднее время ответа, а также p90 и p99. У резидентных прокси эти значения выше из-за "последней мили", но задержки обычно более стабильны.
-
Status Codes: отслеживайте количество ответов 403/429 и 5xx по хостам и ASN. Резкий рост 403 для конкретного пула IP обычно означает, что подсеть начали блокировать.
-
Session Retention: как долго сессии остаются активными без повторного логина. Эта метрика тесно связана с использованием sticky сессий.
-
Throughput: ГБ/с при краулинге — важно для оценки затрат (время GPU часто дешевле, чем хранить 20+ копий HTML страниц). Также рекомендуется мониторить 5-минутный показатель успешности TLS handshake — значение, близкое к 100%, указывает на здоровый пул IP.
Любая система сбора данных должна быть устойчивой к сбоям: при необходимости возвращать пустые результаты, повторять запросы с backoff и отслеживать долю ошибок для каждого прокси. Например, можно ограничивать число запросов на IP для каждого домена и подстраивать лимиты по ответам 403/429, уважать заголовки Retry-After и заменять "сожженные" IP.
Топ 5 прокси провайдеров для задач LLM
Ниже приведена сравнительная таблица пяти прокси провайдеров, которых часто упоминают в контексте AI/LLM нагрузок (исходя из наличия резидентных и мобильных пулов, масштабируемости и возможностей сбора данных). Для каждого провайдера указаны типы прокси, геопокрытие, методы аутентификации, модель ценообразования и антиблокировочные функции.
| Провайдер | URL | Типы прокси | Геопокрытие | Пропускная способность / Задержка | Методы аутентификации | Модель ценообразования (Residential proxies) | Anti‑Bot функции | Плюсы / Минусы |
|---|---|---|---|---|---|---|---|---|
| NodeMaven | https://nodemaven.com/ | Residential, Mobile | 150+ стран, 1400+ городов по всему миру | Высокая (чистые IP и sticky сессии) | Логин/пароль, IP whitelist | Pay‑as‑you‑go и месячные планы ($2.86-$6.18/GB) | Sticky сессии до 24 ч, фильтр качества IP | Плюсы: высокое качество "чистых" IP, sticky сессии, геотаргетинг. Минусы: цена может быть выше, чем у бюджетных альтернатив. |
| BrightData | https://brightdata.com/ | Residential, Datacenter, Mobile | 195+ стран, обширный глобальный пул | Высокая (enterprise уровень) с большой IP сетью | Логин/пароль, API keys | Тарификация по трафику ($5–$8/GB pay‑as‑you‑go, более крупные месячные пакеты) | Продвинутый обход CAPTCHA и управление сессиями | Плюсы: огромный пул IP, лучший вариант для enterprise, гибкое таргетирование. Минусы: сложное ценообразование, дорого для небольших задач. |
| ProxyScrape | https://proxyscrape.com/ | Datacenter, Residential | 55M+ резидентных IP, глобальное покрытие (195 стран) | Средняя (большой, но более "универсальный" пул) | API keys, возможны логин и пароль | Гибкие планы ($1.5-$4.85) | Базовая ротация IP | Плюсы: доступно и гибко. Минусы: качество отличается в зависимости от пула и региона. |
| ProxyEmpire | https://proxyempire.io/ | Residential, Mobile, Datacenter | Глобальное покрытие (миллионы IP) по заявлению провайдера | Средне-высокая (оптимизированные ротационные пулы) | Логин/пароль | Pay‑as‑you‑go (например, старт от $3.5/GB) и небольшие планы | Ротация IP и управление сессиями | Плюсы: гибкие настройки ротации, подходит для смешанных нагрузок. Минусы: пул меньше, чем у топовых enterprise провайдеров. |
| DataImpulse | https://dataimpulse.com/ | Residential, Mobile, Datacenter | 100+ стран, поддержка нескольких регионов | Средняя (хорошая сеть, доступная цена) | Логин/пароль | Pay‑as‑you‑go (часто около ~$1/GB residential) | Базовая ротация IP | Плюсы: очень доступно, несколько типов прокси. Минусы: пул IP меньше по сравнению с гигантами. |
Примечание о ценах. Стоимость прокси сервисов может сильно различаться: датацентровые прокси обычно стоят доли доллара за ГБ, а резидентные и мобильные могут стоить несколько долларов и выше за ГБ. Модели оплаты чаще всего либо по трафику (pay-as-you-go/GB), либо по подписке на IP. Для операций большого масштаба нередко выгоднее гибридная схема (оплата за IP для стабильных сессий плюс оплата за ГБ для большого объема запросов).
Мониторинг и измерение производительности
Чтобы обеспечить качество данных и эффективность обучения, следует отслеживать такие метрики:
-
Качество данных: доля валидных, непустых и не поврежденных результатов. Для LLM критично, чтобы собранный текст был осмысленным и релевантным.
-
Покрытие: количество собранных страниц/документов и ширина охвата (разные домены, языки, регионы).
-
Скорость сбора: документов в день, включая среднюю задержку запросов через прокси.
-
Метрики обучения: после обучения — перплексия, точность на валидации и динамика функции потерь. Сильные результаты показывают, что конвейер данных работает корректно.
-
Метрики прокси: success rate (повторы и ошибки), перцентили задержки (p50/p90), число активных сессий и заблокированных IP.
Также рекомендуется мониторить Handshake Success Rate (TLS; значение, близкое к 100%, означает "здоровые" IP) и распределение кодов ответов (403/429) по автономным системам. Более низкая успешность (например, частые ошибки аутентификации прокси) указывает на плохое качество соединения.
Оптимизация затрат
Даже без жестких бюджетных ограничений важно оптимизировать расходы:
-
Покупайте под потребности: выбирайте между pay-as-you-go и месячными подписками. Месячные планы обычно дешевле, поэтому если вы понимаете ожидаемый расход, они чаще оказываются выгоднее.
-
Балансируйте типы прокси: высокоприоритетные цели направляйте на резидентные прокси, а менее критичные — на датацентровые, чтобы снижать стоимость.
-
Используйте альтернативные источники данных: где возможно, опирайтесь на scraper API или готовые датасеты (например, Common Crawl, SQL дампы Wikipedia), чтобы уменьшить потребность в скрейпинге. Это может существенно сократить расход прокси.
-
Оптимизируйте конвейер данных: уменьшайте объем, который попадет в обучение (дедупликация, предварительная фильтрация), чтобы экономить ресурсы GPU. Например, если вы собрали 1 ТБ данных через прокси, но после дедупликации осталось только 100 ГБ, вы фактически экономите около 90% вычислительных затрат.
Заключение
Обучение LLM — сложный процесс, который требует мощной инфраструктуры, грамотно спроектированного конвейера данных и специализированных инструментов. Прокси серверы играют критически важную роль на этапе сбора данных, обеспечивая масштабируемость, разнообразие и постоянный приток свежей информации в модель. Правильный выбор типов прокси (резидентные, датацентровые, мобильные) и режимов (ротация vs sticky) имеет решающее значение для результата.
Мы рекомендуем подходить к проектированию системы LLM как к инженерной задаче: сегментировать потоки данных по требованиям к сессиям и уровню доверия, внедрить мониторинг "здоровья" прокси и данных, а также итеративно улучшать стратегии ротации и повторов. Использование качественных прокси провайдеров (как в списке выше) обеспечит высокий процент успешного краулинга. И главное: реальная стоимость модели — это не только время GPU, но и полнота и качество данных. Сбалансированное сочетание быстрого доступа и "человеческих" паттернов трафика, собранных через прокси, заметно улучшит итоговые результаты обучения.














