
У цій статті ми детально розглянемо архітектуру та інфраструктуру для навчання великих мовних моделей (LLM), з особливим акцентом на роль проксі-серверів у зборі даних та забезпеченні масштабованості. LLM навчають на колосальних обсягах тексту (наприклад, GPT-3, близько 300 мільярдів токенів ≈ 45 ТБ тексту), тож конвеєр даних передбачає багатоступеневу обробку: краулінг, очищення, дедуплікацію, фільтрацію, токенізацію та розподілене навчання. Проксі є основою цього конвеєра, адже вони дають змогу збирати вебдані у великих масштабах, допомагають уникати блокувань, керувати геолокацією та рівномірно розподіляти навантаження.
Ми охопимо усі етапи LLM-конвеєра (від збору й підготовки даних до розподіленого навчання, безпеки, моніторингу та розгортання) і покажемо, де саме та чому варто використовувати проксі. Окремо розглянемо типи проксі (резидентські, датацентрові, мобільні), а також їхню продуктивність і практичні сценарії застосування. Крім того, у таблиці порівняємо п’ять провідних проксі-провайдерів для задач, пов’язаних з LLM.
Немає часу читати? NodeMaven є найкращим проксі-провайдером для навчання LLM.
Етапи конвеєра даних для LLM
Навчання LLM починається з формування великого текстового корпусу з різноманітних джерел: Common Crawl, вебсайтів, енциклопедій, наукових статей, книжок, репозиторіїв коду тощо. Однак просто взяти весь веб недостатньо, дані мають бути актуальними, різноманітними та якісними. Саме тому багато лабораторій безперервно сканують нові сторінки, щоб моделі залишалися "свіжими" (інакше модель на кшталт GPT-4, навчена на даних до 2021 року, не зможе відповідати на запитання про події 2025 року).
Конвеєр обробки даних для LLM включає такі ключові кроки:
-
Краулінг – завантаження сирих HTML/JSON/медіа через мережу;
-
Очищення – видалення HTML-шаблонів, реклами та скриптів;
-
Дедуплікація – усунення точних і майже дубльованих документів;
-
Фільтрація – відбір за якістю, виключення токсичного або персонального контенту, мов тощо;
-
Навчання – токенізація та навчання на кластерах GPU/TPU. Усі ці етапи потребують продуманої інфраструктури та моніторингу.
Нижче наведено наочну схему цього конвеєра (з акцентом на роль проксі):
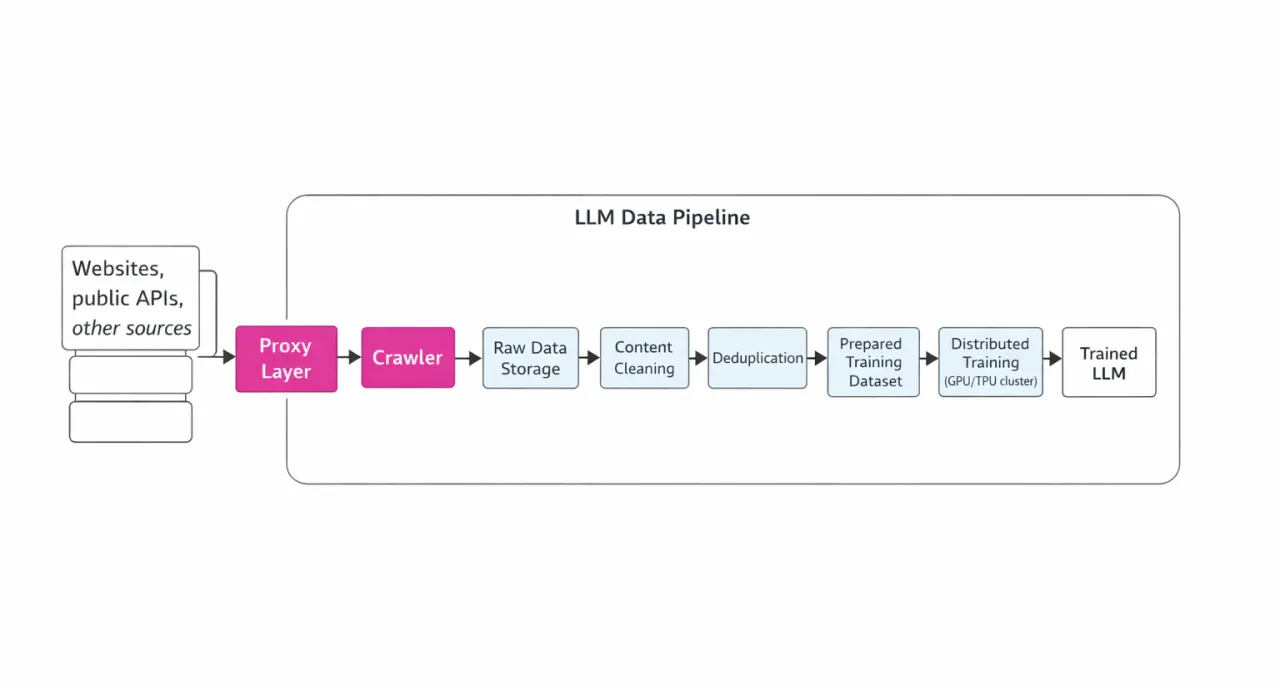
Краулінг і роль проксі
Під час краулінгу потрібно одночасно надсилати мільйони HTTP(S)-запитів до різних сайтів. Проте антибот-захист і ліміти за IP часто блокують масштабні кампанії зі скрейпінгу. Саме тут стають у пригоді проксі-сервери. Проксі дають змогу розподіляти запити між тисячами IP-адрес і геолокацій, істотно знижуючи ймовірність блокувань. Особливо важливі ротаційні проксі, оскільки вони дозволяють безперервно збирати дані без простоїв. Проксі також допомагають імітувати запити від реальних користувачів, зменшуючи ризик виявлення. Навіть під час доступу до API (наприклад, інших сервісів або генерації синтетичних даних за допомогою LLM) проксі допомагають розподіляти навантаження та дотримуватися лімітів запитів.
Втім, важливо враховувати: проксі знімають технічні обмеження (IP-блокування, rate limits, локалізацію), але не обходять юридичні заборони. Використання проксі не скасовує необхідності дотримуватися robots.txt та чинного законодавства, тож навіть із проксі слід поважати правила сайтів і юридичні вимоги під час збору даних.
Обробка даних (очищення, фільтрація, дедуплікація)
Після збору сирого контенту стартує етап попередньої обробки. Наприклад, AWS описує, що "перший крок у конвеєрі, це витягування та збирання даних із різних джерел і форматів (PDF, HTML, JSON, документи Office)", із використанням OCR, HTML-парсерів та подібних інструментів. На цьому етапі прибирають небажані елементи (HTML-теги, неанглійські символи) і нормалізують текст.
Далі дані фільтруються за різними критеріями. Рекомендовані патерни фільтрації включають метадані (наприклад, URL або назву файлу), контент (виключення токсичного або PII-контенту), мову, надмірні повтори або спам, довжину документа, а також використання регулярних виразів чи простих класифікаторів якості. Наприклад, можна відкидати тексти з небажаною лексикою або "шумними" форматами або, навпаки, залишати лише документи на конкретні теми.
Після фільтрації виконується дедуплікація: зібраний датасет може містити однакові або майже однакові документи (рерайти, дублікати HTML-сторінок тощо). Алгоритми на кшталт MinHash або SimHash дають змогу виявляти точні та майже дубльовані копії й видаляти їх. Це важливо, оскільки дублікати погіршують якість навчання (модель просто "запам’ятовує" повторюваний текст).
Останній крок перед навчанням, це фінальне очищення: класифікація контенту (оцінка якості, видалення токсичних фрагментів, PII). Наприклад, датасети перевіряють на наявність персональних даних і відфільтровують неприйнятний контент, забезпечуючи безпечність моделі та узгодженість даних. Після цього підготовлений текстовий корпус передають на етап навчання (токенізація, формування батчів тощо).
Інфраструктура та розподілене навчання
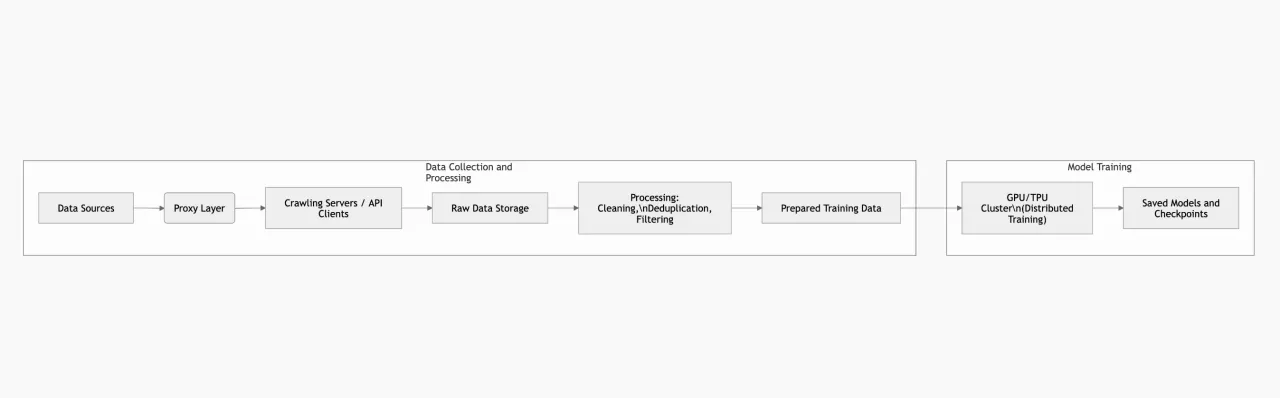
Навчання великої LLM потребує кластерів із сотнями або навіть тисячами GPU/TPU. Через обмеження пам’яті та обчислювальних ресурсів GPU використовують різні типи паралелізму: тензорний паралелізм (розподіл шарів моделі між пристроями), конвеєрний паралелізм (різні шари послідовно виконуються на різних пристроях) і паралелізм за даними (повна копія моделі на кожному пристрої, але обробка різних батчів даних). Така комбінація (як у NVIDIA Megatron-LM) дозволяє масштабувати навчання до тисяч GPU. Наприклад, Megatron-LM навчав модель із 1 трильйоном параметрів на 3 072 GPU. Результат, понад 500 петафлопс ефективної продуктивності. Зазвичай такі системи спираються на високошвидкісні мережі (InfiniBand), сервери з великим обсягом пам’яті та SSD для зберігання чекпойнтів.
Ключовий компонент, це партиційоване сховище даних (Data Lakes або файлові системи, оптимізовані під великі дані), де зберігаються результати краулінгу. Зазвичай використовують кілька рівнів зберігання: cold storage (доступ рідше) і hot storage (безпосередньо підживлює навчальний конвеєр). Також критично важливі системи моніторингу кластера (наприклад, Prometheus/Grafana) для відстеження завантаження GPU, швидкості навчання, використання пам’яті, споживання електроенергії та іншого.
Приклад архітектури навчання: Нижче наведено спрощену схему взаємодії компонентів: збір даних через проксі, перетворення та зберігання даних і навчальні кластери. Це лише один із можливих підходів до проєктування.
Безпека, приватність і відповідність вимогам
Працюючи з даними для LLM, важливо враховувати етичні та правові вимоги. Це включає захист авторських прав і персональних даних, дотримання ліцензійних обмежень і GDPR, а також майбутніх регуляцій щодо ШІ (наприклад, EU AI Act вимагає прозорості та контролю якості даних). Використання проксі не знімає відповідальності: датасети мають формуватися з публічно доступних і дозволених джерел.
Критичною є й безпека самої навчальної системи. Кластери потрібно захищати від несанкціонованого доступу (мережеві фаєрволи, сегментація), ПЗ слід регулярно оновлювати, а дані в сховищах необхідно шифрувати. Моніторинг безпеки (IDS/IPS, логування запитів) допомагає виявляти аномалії в інфраструктурі.
Проксі-сервери: типи та характеристики
Основні типи проксі
-
Резидентські проксі – IP-адреси реальних користувачів. Сайти рідко їх блокують, тому показник успішності зазвичай становить 95–99%. Сьогодні це вважається найпопулярнішим варіантом для навчання LLM. Резидентські проксі ідеальні там, де потрібен максимально "людяний" трафік (соцмережі, захищені сайти, локалізовані версії). Додатково вони дають змогу таргетувати до рівня міста, що може бути важливим для певних задач.
-
Мобільні проксі – проксі з IP-адресами мобільних операторів. Вони ще "анонімніші" за резидентські, адже сайти рідко їх блокують через те, що багато користувачів одночасно можуть ділити одну IP-адресу. Зазвичай їх використовують, коли резидентських проксі недостатньо або коли потрібно емулювати мобільного користувача.
-
Датацентрові проксі – IP-адреси, розміщені в датацентрах (AWS, Azure тощо). Вони швидкі, недорогі й забезпечують високу пропускну здатність. Проте їх легко виявити: підмережі датацентрів часто блокуються системами безпеки. Загальний показник успішності на захищених сайтах становить близько 40–60%, зате затримка мінімальна. Такий тип підходить для масового збору даних із сайтів зі слабким антибот-захистом.
Усі ці типи проксі зазвичай розглядають у контексті ротаційних проксі, які можуть відрізнятися частотою зміни IP-адреси. Розгляньмо детальніше.
-
Є ротаційні проксі, що змінюють IP після кожного запиту або через заданий інтервал часу. Такі проксі забезпечують високий рівень анонімності, адже пул може містити мільйони адрес, доступних для використання. Вони корисні для коротких запитів у стилі "отримав і забув".
-
Ротаційні проксі з фіксованим IP – по суті, це ті самі ротаційні проксі, але IP-адреса не змінюється після кожного запиту. Натомість вона зберігається незмінною максимально довго. Вони ідеальні для багатокрокових операцій (логіни, форми тощо), де зміна IP спричинить повторну автентифікацію. Іншими словами, sticky проксі підтримують одну IP-адресу на всю сесію, імітуючи сесію реального користувача, тоді як стандартні ротаційні проксі видають новий IP на кожен запит. Обидва підходи можна комбінувати залежно від задачі.
Продуктивність і безпека проксі
Вибір типу проксі завжди є компромісом між швидкістю та надійністю. Датацентрові проксі лідирують за пропускною здатністю (вони в 3–4 рази швидші за резидентські), але їх частіше блокують. Резидентські проксі можуть забезпечити найвищу якість доступу (приблизно 99% успішності), проте мають більші часи відповіді. Мобільні проксі найдорожчі й повільніші, зате забезпечують найвищий рівень довіри (мережі рівня операторів зв’язку).
Антибот-системи спираються на ланцюжок сигналів: IP, таймінги, заголовки та поведінкове фингерпринтування. Проксі-сервіс пом’якшує більшість із них, розподіляючи трафік між IP і геолокаціями, а інколи ще й керуючи таймінгами запитів, щоб імітувати природні затримки. Водночас проксі не гарантують ідеального результату. Якщо система виявить очевидно автоматизовану поведінку, антибот-захист усе одно може активувати CAPTCHA.
Інтеграція проксі у збір даних
Реалізація пулу проксі в коді є стандартною задачею. Наприклад, у Python з бібліотекою requests можна налаштувати проксі так:
import requests
proxies = {
"http": "http://user:pass@proxy.example.com:port",
"https": "https://user:pass@proxy.example.com:port",
}
response = requests.get("http://example.com", proxies=proxies)
Для довгих сесій (наприклад, з автентифікацією) можна використовувати requests.Session() і повторно застосовувати той самий проксі або вказувати на рівні сервісу параметр session_id чи sticky. У фреймворках на кшталт Scrapy є middleware для ротації проксі: ви надаєте список IP, і Scrapy автоматично циклічно їх використовує, контролюючи частоту запитів. В інструментах автоматизації браузера (Selenium, Playwright) проксі передаються через налаштування браузера (--proxy-server=http://host:port).
Важливо правильно обрати модель автентифікації. Проксі-сервіси зазвичай підтримують:
-
Логін:пароль (Basic Auth) – стандарт для HTTP/HTTPS-проксі (як показано вище).
-
API ключ/токен – використовується для доступу до сервісів (часто через HTTP-заголовки).
-
Allowlist IP – деякі провайдери дозволяють додати ваші сервери до білого списку, щоб користуватися проксі без автентифікації.
Моніторинг і оптимізація збору даних
Щоб забезпечити стабільний конвеєр даних, важливо відстежувати ключові метрики:
-
Request Success Rate: частка запитів, що повертають валідні дані замість помилок (4xx/5xx). В ідеалі для цільових доменів цей показник має бути понад 95%.
-
Latency: середній час відповіді, а також p90 і p99. Для резидентських проксі ці значення вищі через фактор "останньої милі", але зазвичай затримка в них більш стабільна.
-
Status Codes: відстежуйте кількість відповідей 403/429 і 5xx за хостом та ASN. Різке зростання 403 для конкретного пулу IP зазвичай означає, що підмережу блокують.
-
Session Retention: як довго сесії залишаються активними без повторного входу. Ця метрика тісно пов’язана з використанням sticky-сесій.
-
Throughput: ГБ/с під час краулінгу, важливо для оцінки витрат (час GPU часто дешевший за зберігання 20+ копій HTML-сторінок). Також рекомендується моніторити 5-хвилинні показники успішності TLS handshake, близько 100% свідчить про здоровий пул IP.
Будь-яка система збору даних має бути стійкою до збоїв: за потреби повертати порожні результати, повторювати запити з backoff і відстежувати рівень помилок для кожного проксі. Наприклад, можна обмежувати кількість запитів з одного IP на домен і коригувати її залежно від відповідей 403/429, дотримуватися заголовків Retry-After і замінювати "спалені" IP.
Топ-5 проксі-провайдерів для задач LLM
Нижче наведено порівняльну таблицю п’яти проксі-провайдерів, яких часто згадують у контексті AI/LLM-навантажень (на основі наявності резидентських і мобільних пулів, масштабованості та можливостей збору даних). Для кожного провайдера ми вказуємо типи проксі, географічне покриття, методи автентифікації, модель ціни та антиблокувальні функції.
| Провайдер | URL | Типи проксі | Геопокриття | Пропускна здатність / Затримка | Методи автентифікації | Модель ціни (Резидентські проксі) | Anti‑Bot функції | Плюси / Мінуси |
|---|---|---|---|---|---|---|---|---|
| NodeMaven | https://nodemaven.com/ | Резидентські, Мобільні | 150+ країн, 1400+ міст у світі | Висока (чисті IP та sticky-сесії) | Логін/пароль, IP whitelist | Pay‑as‑you‑go та місячні плани ($2.86-$6.18/GB) | Sticky-сесії до 24 год, фільтр якості IP | Плюси: високоякісні "чисті" IP, sticky-сесії, геотаргетинг. Мінуси: ціна може бути вищою, ніж у бюджетних альтернатив. |
| BrightData | https://brightdata.com/ | Резидентські, Датацентрові, Мобільні | 195+ країн, великий глобальний пул | Висока (enterprise-рівень) із великою IP-мережею | Логін/пароль, API ключі | Тарифікація за трафіком ($5–$8/GB pay‑as‑you‑go, більші місячні пакети) | Розширений обхід CAPTCHA та контроль сесій | Плюси: величезний пул IP, найкраще для enterprise, гнучке таргетування. Мінуси: складне ціни, дорого для невеликих задач. |
| ProxyScrape | https://proxyscrape.com/ | Датацентрові, Резидентські | 55M+ резидентських IP, глобальне покриття (195 країн) | Середня (великий, але більш "універсальний" пул) | API ключі, можливі логін/пароль | Гнучкі плани ($1.5-$4.85) | Базова ротація IP | Плюси: доступно та гнучко. Мінуси: якість відрізняється залежно від пулу та регіону. |
| ProxyEmpire | https://proxyempire.io/ | Резидентські, Мобільні, Датацентрові | Глобальне покриття (мільйони IP) за заявами провайдера | Середня-Висока (оптимізовані ротаційні пули) | Логін/пароль | Pay‑as‑you‑go (наприклад, старт від $3.5/GB) та невеликі плани | Ротація IP та керування сесіями | Плюси: гнучкі налаштування ротації, добре для змішаних навантажень. Мінуси: пул менший, ніж у топових enterprise-провайдерів. |
| DataImpulse | https://dataimpulse.com/ | Резидентські, Мобільні, Датацентрові | 100+ країн, підтримка кількох регіонів | Середня (надійна мережа, доступна ціна) | Логін/пароль | Pay‑as‑you‑go (часто близько ~$1/GB резидентські) | Базова ротація IP | Плюси: дуже доступно, кілька типів проксі. Мінуси: менший пул IP порівняно з гігантами. |
Примітка щодо ціни. Ціни на проксі-сервіси можуть істотно відрізнятися: датацентрові проксі зазвичай коштують частки долара за GB, тоді як резидентські й мобільні можуть коштувати кілька доларів або більше за GB. Моделі оплати зазвичай або за трафік (pay-as-you-go/GB), або підписка за IP. Для операцій у великому масштабі часто вигідніше застосовувати гібридну модель (за IP для стабільних сесій і за GB для великого обсягу запитів).
Моніторинг і вимірювання продуктивності
Щоб забезпечити якість даних та ефективність навчання, слід відстежувати такі метрики:
-
Якість даних: відсоток валідних, непорожніх і неушкоджених результатів. Для LLM критично, щоб зібраний текст був змістовним і релевантним.
-
Покриття: кількість зібраних сторінок/документів і ширина охоплення (різні домени, мови, регіони).
-
Швидкість збору: документів на добу, включно із середньою затримкою запитів через проксі.
-
Метрики навчання: після навчання, perplexity, точність на валідації та тренди функції втрат. Сильні результати свідчать, що конвеєр даних працює коректно.
-
Метрики проксі: показник успішності (повтори й збої), перцентилі затримки (p50/p90), кількість активних сесій і заблокованих IP.
Також рекомендується моніторити Handshake Success Rate (TLS; значення, близькі до 100%, вказують на здорові IP) і розподіл кодів відповіді (403/429) за автономними системами. Нижчий показник успішності (наприклад, часті збої автентифікації проксі) свідчить про низьку якість з’єднання.
Оптимізація витрат
Навіть без жорстких бюджетних обмежень важливо оптимізувати витрати:
-
Купуйте під потреби: обирайте між pay-as-you-go та місячною підпискою. Місячні плани зазвичай дешевші, тому якщо ви знаєте очікуване споживання, вони часто вигідніші.
-
Баланс типів проксі: високопріоритетні цілі направляйте на резидентські проксі, а менш критичні, на датацентрові, щоб зменшити витрати.
-
Використовуйте альтернативні джерела даних: де можливо, покладайтеся на scraper API або вже наявні датасети (наприклад, Common Crawl, SQL-дампи Wikipedia), щоб зменшити потребу в скрейпінгу. Це може суттєво скоротити використання проксі.
-
Оптимізуйте конвеєр даних: зменшуйте обсяг даних, що потрапляє в навчання (дедуплікація, попередня фільтрація), щоб економити ресурси GPU. Наприклад, якщо ви зібрали через проксі 1 ТБ даних, але після дедуплікації залишилося лише 100 ГБ, ви фактично заощаджуєте близько 90% обчислювальних витрат.
Висновок
Навчання LLM, це складний процес, який потребує потужної інфраструктури, добре спроєктованого конвеєра даних і спеціалізованих інструментів. Проксі-сервери відіграють критично важливу роль на етапі збору даних, забезпечуючи масштабованість, різноманітність і безперервний потік свіжих даних у модель. Правильний вибір типів проксі (резидентські, датацентрові, мобільні) і режимів (ротаційні чи sticky) є ключовим для успіху.
Ми рекомендуємо підходити до проєктування LLM-систем як до інженерної задачі: сегментувати потоки даних залежно від вимог до сесій і рівня довіри, впроваджувати моніторинг стану проксі та даних і поступово вдосконалювати стратегії ротації та повторних спроб. Використання якісних проксі-провайдерів (як наведено вище) забезпечить високий показник успішного краулінгу. Найважливіше, пам’ятайте, що реальна вартість моделі, це не лише час GPU, а й повнота та якість даних. Збалансоване поєднання швидкого доступу та "людяних" патернів трафіку, зібраних через проксі, суттєво покращить фінальні результати навчання.














